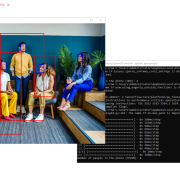
Document Orientation Correction
Another application of the problem explained in the article “Discovering a small image inside a large image using Python and OpenCV” is that you can use this code to find a special sign in a ID card Scan and make certain changes based on that.
For example, here we have given the program a type of sample certificate that has been scanned in reverse, and after finding the sign in the upper right corner of the card, we rotate it as many times as necessary to show the certificate image in the right direction.
Sample code:
import cv2
def find_image_in_larger_image(small_image, large_image):
# Read images
# Check if images are loaded successfully
if small_image is None or large_image is None:
print(“Error: Unable to load images.”)
return None
# Get dimensions of both images
small_height, small_width = small_image.shape
large_height, large_width = large_image.shape
# Find the template (small image) within the larger image
result = cv2.matchTemplate(large_image, small_image, cv2.TM_CCOEFF_NORMED)
# Define a threshold to consider a match
threshold = 0.6
# Find locations where the correlation coefficient is greater than the threshold
locations = cv2.findNonZero((result >= threshold).astype(int))
# If no match is found
if locations is None:
return None
# Determine the position of the matched areas
matched_positions = []
for loc in locations:
x, y = loc[0]
if x < large_width / 2:
position_x = “left”
otherwise:
position_x = “right”
if y < large_height / 2:
position_y = “top”
otherwise:
position_y = “bottom”
matched_positions.append((position_x, position_y))
return matched_positions
# Example usage
small_image_path = “mark.jpg”
large_image_path = “card.jpg”
small_image = cv2.imread(small_image_path, cv2.IMREAD_GRAYSCALE)
large_image = cv2.imread(large_image_path, cv2.IMREAD_GRAYSCALE)
rotated_large_image=large_image
positions = find_image_in_larger_image(small_image, large_image)
max_rotation = 10 # Set the maximum rotation limit
if positions:
position_x, position_y = positions[0]
print(“Position: {}, {}”.format(position_x, position_y))
while max_rotation>0:
max_rotation-=1
rotated_large_image = cv2.rotate(rotated_large_image, cv2.ROTATE_90_CLOCKWISE)
positions = find_image_in_larger_image(small_image, rotated_large_image)
if positions:
position_x, position_y = positions[0]
print(“Position: {}, {}”.format(position_x, position_y))
if(position_x==’right’ and position_y==’top’):
cv2.imshow(“Mark”, small_image)
cv2.imshow(“Original”, large_image)
cv2.imshow(“Result”, rotated_large_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
max_rotation=0
otherwise:
print(“No match found after {} rotations.”.format(10-max_rotation))
otherwise:
print(“No match found after {} rotations.”.format(10-max_rotation))