Apache flume introduction
The past few years have seen tremendous growth in the development and adoption of Big Data technologies. Hadoop and related platforms are powering the next wave of data analytics over increasingly large amounts of data. The data produced today will be dwarfed by what is expected tomorrow, growing at an ever-increasing rate as the digital revolution engulfs all aspects of our existence. The barrier to entry in this new age of massive data volumes is of course the obvious one: how do you get all this data in your cluster to begin with? Clearly, this data is produced in a wide spectrum of sources spread across the enterprise, and has an interesting mix of interaction, machine, sensor, and social data among others. Any operator who has dealt with similar challenges would no doubt agree that it is nontrivial, if not downright hard, to build a system that can route this data into your clusters in a cost-effective manner.Apache.
What is flume?
Flume is exactly built to handle this challenge
In addition to structured data in databases, another common source of data is log files, which usually come in the form of continuous (streaming) incremental files often from multiple source machines. In order to use this type of data for data science with Hadoop, we need a way to ingest such data into HDFS.
Apache Flume is a tool in the Hadoop ecosystem that provides capabilities for efficiently collecting, aggregating and bringing in large amounts of data into Hadoop. Examples of large amounts of data are log data, network traffic data, social media data, geo-location data, sensor and machine data and email message data. Flume provides several features to manage data. It lets users ingest data from multiple data sources into Hadoop. It protects systems from data spikes when the rate of data inflow exceeds the rate at which data is written. Flume NG guarantees data delivery using channel based transactions. Flume scales horizontally to process more data streams and data volumes.
Pushing data to HDFS and similar storage systems using an intermediate system is a very common use case. There are several systems, like Apache Flume, Apache Kafka, Facebook’s Scribe, etc., that support this use case. Such systems allow HDFS and HBase clusters to handle sporadic bursts of data without necessarily having the capacity to handle that rate of writes continuously. These systems act as a buffer between the data producers and the final destination. By virtue of being buffers, they are able to balance out the impedance mismatch between the producers and consumers, thus providing a steady state of flow.
Scaling these systems is often far easier than scaling HDFS or HBase clusters. Such systems also allow the applications to push data without worrying about having to buffer the data and retry in case of HDFS downtime, etc.Most such systems have some fundamental similarities. Usually, these systems have components that are responsible for accepting the data from the producer, through an RPC call or HTTP (which may be exposed via a client API).
They also have components that act as buffers where the data is stored until it is removed by the components that move the data to the next hop or destination. In this chapter, we will discuss the basic architecture of a Flume agent and how to configure Flume agents to move data from various applications to HDFS or HBase.
Apache Hadoop is becoming a standard data processing framework in large enterprises. Applications often produce massive amounts of data that get written to HDFS, the distributed file system that forms the base of Hadoop. Apache Flume was conceived as a system to write data to Apache Hadoop and Apache HBase in a reliable and scalable fashion.
As a result, Flume’s HDFS and HBase Sinks provide a very rich set of features that makes it possible to write data in any format that is supported by these systems and in a MapReduce/Hive/Impala/Pig–friendly way. In this book, we will discuss why we need a system like Flume, its design and implementation, and the various features of Flume that make it highly scalable, flexible, and reliable.
The Need for Flume
Why do we really need a system like Flume?
Why not simply write data directly to HDFS from every application server that produces data?
In this section, we will discuss why we need such a system, and what it adds to the architecture.Messaging systems that isolate systems from each other have existed for a long time—Flume does this in the Hadoop context.
Flume is specifically designed to push data from a massive number of sources to the various storage systems in the Hadoop ecosystem, like HDFS and HBase.In general, when there is enough data to be processed on a Hadoop cluster, there is usually a large number of servers producing the data. This number could be in the hundreds or even thousands of servers. Such a huge number of servers trying to write data to an HDFS or HBase cluster can cause major problems, for multiple reasons.HDFS requires that exactly one client writes to a file—as a result, there could be thousands of files being written to at the same time. Each time a file is created or a new block is allocated, there is a complex set of operations that takes place on the name node.
Such a huge number of operations happening simultaneously on a single server can cause the server to come under severe stress. Also, when thousands of machines are writing a large amount of data to a small number of machines, the network connecting these machines may get overwhelmed and start experiencing severe latency.In many cases, application servers residing in multiple data centers aggregate data in a single data center that hosts the Hadoop cluster, which means the applications have to write data over a wide area network (WAN). In all these cases, applications might experience severe latency when attempting to write to HDFS or HBase.
If the number of servers hosting the applications or the number of applications writing data increases, the latency and failure rate are likely to increase.
As a result, considering HDFS cluster and network latencies becomes an additional concern while designing the software that is writing to HDFS.Most applications see production traffic in predictable patterns, with a few hours of peak traffic per day and much less traffic during the rest of the day.
To ensure an application that is writing directly to HDFS or HBase does not lose data or need to buffer a lot of data, the HDFS or HBase cluster needs to be configured to be able to handle peak traffic with little or no latency.
All these cases make it clear that it is important to isolate the production applications from HDFS or HBase and ensure that production applications push data to these systems in a controlled and organized fashion.
Flume is designed to be a flexible distributed system that can scale out very easily and is highly customizable. A correctly configured Flume agent and a pipeline of Flume agents created by connecting agents with each other is guaranteed to not lose data, provided durable channels are used.The simplest unit of Flume deployment is a Flume agent. It is possible to connect one Flume agent to one or more other agents. It is also possible for an agent to receive data from one or more agents.
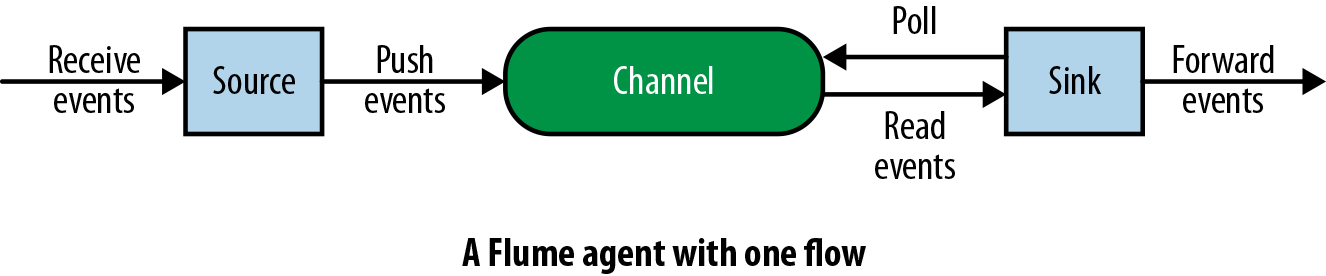
By connecting multiple Flume agents to each other, a flow is established. This chain of Flume agents can be used to move data from one location to another—specifically, from applications producing data to HDFS, HBase, etc.By having a number of Flume agents receive data from application servers, which then write the data to HDFS or HBase (either directly or via other Flume agents), it is possible to scale the number of servers and the amount of data that can be written to HDFS by simply adding more Flume agents.Each Flume agent has three components: the source, the channel, and the sink.
The source is responsible for getting events into the Flume agent, while the sink is responsible for removing the events from the agent and forwarding them to the next agent in the topology, or to HDFS, HBase, Solr, etc
Is Flume a Good Fit?
Flume represents data as events. Events are very simple data structures, with a body and a set of headers. The body of the event is a byte array that usually is the payload that Flume is transporting. The headers are represented as a map with string keys and string values. Headers are not meant to transfer data, but for routing purposes and to keep track of priority, severity of events being sent, etc. The headers can be used to add event IDs or UUIDs to events as well.
Each event must essentially be an independent record, rather than a part of a record. This also imposes the requirement that each event be able to fit in the memory of the Flume agent JVM. If a File Channel is being used, then there should be enough disk space to accommodate this. If data cannot be represented as multiple individual records, Flume might not be a good fit for the use case.
Flume is primarily meant to push data from a large number of production servers to HDFS, HBase, etc. In cases where Flume is not a good fit, there is often an easier method, like Web HDFS or the HBase HTTP API, that can be used to write data. If there are only a handful of production servers producing data and the data does not need to be written out in real time, then it might also make sense to just move the data to HDFS via Web HDFS or NFS, especially if the amount of data being written out is relatively small—a few files of a few GB every few hours will not hurt HDFS. In this case, planning, configuring, and deploying Flume may not be worth it. Flume is really meant to push events in real time where the stream of data is continuous and its volume reasonably large.
As noted earlier, the simplest unit of deployment of Flume is called a Flume agent. An agent is a Java application that receives or generates data and buffers it until it is eventually written to the next agent or to a storage or indexing system. We will discuss the three main components of Flume agents (sources, channels, and sinks) in the next section.
Streaming / Log Data
Generally, most of the data that is to be analyzed will be produced by various data sources like applications servers, social networking sites, cloud servers, and enterprise servers. This data will be in the form of log files and events.
Log file − In general, a log file is a file that lists events/actions that occur in an operating system. For example, web servers list every request made to the server in the log files.
On harvesting such log data, we can get information about −
- the application performance and locate various software and hardware failures.
- the user behavior and derive better business insights.
The traditional method of transferring data into the HDFS system is to use the put command. Let us see how to use the put command.
HDFS put Command
The main challenge in handling the log data is in moving these logs produced by multiple servers to the Hadoop environment.
Hadoop File System Shell provides commands to insert data into Hadoop and read from it. You can insert data into Hadoop using the put command as shown below.
$ Hadoop fs –put /path of the required file /path in HDFS where to save the file
Problem with put Command
We can use the put command of Hadoop to transfer data from these sources to HDFS. But, it suffers from the following drawbacks −
- Using putcommand, we can transfer only one file at a time while the data generators generate data at a much higher rate. Since the analysis made on older data is less accurate, we need to have a solution to transfer data in real time.
- If we use putcommand, the data is needed to be packaged and should be ready for the upload. Since the webservers generate data continuously, it is a very difficult task.
What we need here is a solutions that can overcome the drawbacks of putcommand and transfer the “streaming data” from data generators to centralized stores (especially HDFS) with less delay.
Problem with HDFS
In HDFS, the file exists as a directory entry and the length of the file will be considered as zero till it is closed. For example, if a source is writing data into HDFS and the network was interrupted in the middle of the operation (without closing the file), then the data written in the file will be lost.
Therefore we need a reliable, configurable, and maintainable system to transfer the log data into HDFS.
Note − In POSIX file system, whenever we are accessing a file (say performing write operation), other programs can still read this file (at least the saved portion of the file). This is because the file exists on the disc before it is closed.
Available Solutions
To send streaming data (log files, events etc..,) from various sources to HDFS, we have the following tools available at our disposal −
Facebook’s Scribe
Scribe is an immensely popular tool that is used to aggregate and stream log data. It is designed to scale to a very large number of nodes and be robust to network and node failures.
Apache Kafka
Kafka has been developed by Apache Software Foundation. It is an open-source message broker. Using Kafka, we can handle feeds with high-throughput and low-latency.
Apache Flume
Apache Flume is a tool/service/data ingestion mechanism for collecting aggregating and transporting large amounts of streaming data such as log data, events (etc…) from various webserves to a centralized data store.
It is a highly reliable, distributed, and configurable tool that is principally designed to transfer streaming data from various sources to HDFS.
Apache Flume Features
There are many core advantages of Apache Flume available. They are:
i. Open source
Apache flume is open source i.e. easily available.
ii. Documentation
There are many good examples and patterns of how these can be applied, is available in its documentation.
iii. Latency
Apache Flume offers high throughput with lower latency.
iv. Configuration
It contains a very declarative configuration.
Follow this link, to know more about Flume configuration & Installation
v. Data Flow
In Hadoop environments, Flume works with streaming data sources which are generated continuously. Such as log files.
vi. Routing
Generally, Flume looks at the payload such as stream data or event. Also, construct a routing which is apt.
vii. Inexpensive
While it comes to maintain Flume, we can say less costly to install, operate and maintain.
viii. Fault Tolerance and Scalable
Apache Flume is highly extensible, reliable, available, horizontally scalable as well as customizable for different sources and sinks. However, that helps in collecting, aggregating and moving a large number of datasets. For example Facebook, Twitter and e-commerce websites.
ix. Distributed
It is inherently distributed in nature.
x. Reliable Message Delivery
It offers reliable message delivery. Basically, in Flume the transactions are channel-based where two transactions (one sender & one receiver) are maintained for each message.
xi. Streaming
It gives us a solution which is reliable and distributed and helps us to ingest online streaming data from various sources (network traffic, social media, email messages, log files etc) in HDFS.
xii. Steady Flow
Flume offers a steady flow of data if the read the write rate, between reading and write operations.
Apache Flume Use Cases – Future Scope in Flume
Use Cases of Flume
As we know while it comes to handling the data flowing to/from the relational database and fast-moving unstructured data we use Flume. However, there are many more cases where we can use Apache Flume. Hence, in this article, we will learn all the possible Apache Flume use cases. But before Flume use cases, we will also learn its brief introduction to understand it well.
So, let’s start exploring Flume Use Cases.
Flume Use Cases
Let’s discuss all the possible Apache Flume Use Cases.
i. While we want to acquire data from a variety of source and store into Hadoop system, we use Apache Flume.
ii. Whenever we need to handle high-velocity and high-volume data into Hadoop system, we go for Apache Flume.
iii. It also helps in the reliable delivery of data to the destination.
iv. When the velocity and volume of data increases, Flume turned as a scalable solution that can run quite easily just by adding more machine to it.
v. Without incurring any downtime Flume dynamically configures the various components of the Flume Architecture.
vi. We can achieve a single point of contact with Flume, for all the various configurations based on which the overall architecture is functioning.
Let’s read about Apache Flume Installation
vii. While it comes to real-time streaming of data we use Apache Flume.
viii. Efficient collection of the log data and ingestion into a centralized store (HDFS, HBase), from multiple servers, we use Flume.
ix. We can collect the data from multiple servers in real-time as well as in batch mode, with the help of Flume.
x. we can easily import Huge volumes of event data generated and analyzed in real-time by social media websites like Facebook and Twitter and various e-commerce websites such as Amazon and Flipkart.
xi. It is possible to collect data from a large set of sources and then move them to multiple destinations with Flume.
xii. Flume also supports Multi-hop flows, fan-in fan-out flows, and contextual routing.
xiii. Moreover, while we have multiple web applications server running, generating logs or us have to move logs at very fast speed to HDFS, we use Apache Flume.
xiv. Also, we use Flume to do a sentiment analysis or to download using crawlers various data from the twitter and then move this data to HDFS.
xv. By using interceptors, in Flume, we can process data in-flight.
xvi. For data masking or filtering, Flume can be very useful.
xvii. It is possible to scale it horizontally.
So, this was all in Flume Use Cases. Hope you like our explanation.
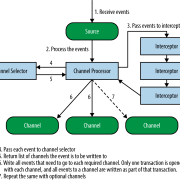
Inside a Flume Agent
Flume architecture
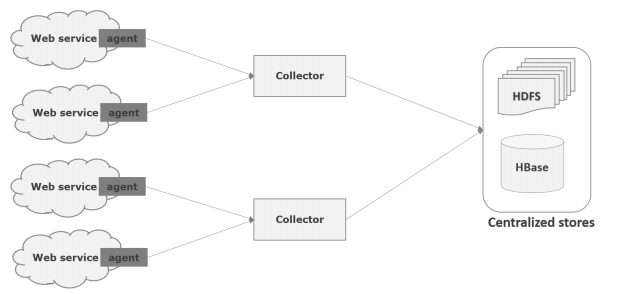
The following illustration depicts the basic architecture of Flume. As shown in the illustration, data generators (such as Facebook, Twitter) generate data which gets collected by individual Flume agents running on them. Thereafter, a data collector (which is also an agent) collects the data from the agents which is aggregated and pushed into a centralized store such as HDFS or HBase
Flume Event
An event is the basic unit of the data transported inside Flume. It contains a payload of byte array that is to be transported from the source to the destination accompanied by optional headers. A typical Flume event would have the following structure:

Flume Agent
Take a look at the following illustration. It shows the internal components of an agent and how they collaborate with each other.
An agent is an independent daemon process (JVM) in Flume. It receives the data (events) from clients or other agents and forwards it to their next destination
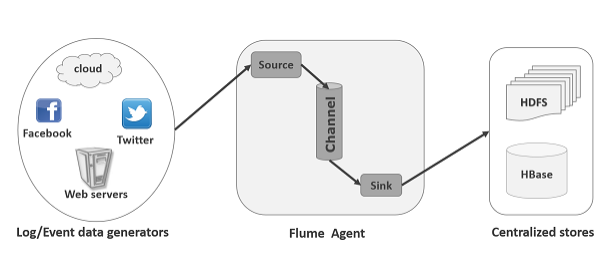
A Flume agent is composed of three components:
- Source— A source receives data from the log/event data generators such as Facebook, Twitter, and other webservers, and transfers it to the channel in the form of Flume events. Data generators like webservers generate data and deliver it to the agent. A source is a component of the agent which receives this data and transfers it to one or more channels. Apache Flume supports several types of sources and each source receives events from a specified data generator. For example, Avro source receives data from the clients which generate data in the form of Avro files. Flume supports the following sources: Avro, Exec, Spooling directory, Net Cat, Sequence generator, Syslog, Multiport TCP, Syslog UDP, and HTTP.
- Channel—A channel is a transient store which receives the events from the source and buffers them till they are consumed by sinks. It acts as a bridge between the sources and the sinks.
These channels are fully transactional and they can work with any number of sources and sinks. Example: JDBC channel, File system channel, Memory channel, etc.
- Sink—Finally, the sink stores the data into centralized stores like HBase and HDFS. It consumes the data (events) from the channels and delivers it to the destination.
The destination of the sink might be another agent or the central stores. Example: HDFS sink.
Flume supports the following sinks: HDFS sink, Logger, Avro, Thrift, IRC, File Roll, Null sink, HBase, and Morphline solr.
As discussed earlier, each Flume agent consists of three major components: sources, channels, and sinks. In this section, we will describe these and other components and how they work together.
Sources are active components that receive data from some other application that is producing the data. There are sources that produce data themselves, though such sources are mostly used for testing purposes. Sources can listen to one or more network ports to receive data or can read data from the local file system. Each source must be connected to at least one channel. A source can write to several channels, replicating the events to all or some of the channels, based on some criteria.
Channels are, in general, passive components (though they may run their own threads for cleanup or garbage collection) that buffer data that has been received by the agent, but not yet written out to another agent or to a storage system. Channels behave like queues, with sources writing to them and sinks reading from them. Multiple sources can write to the same channel safely, and multiple sinks can read from the same channel. Each sink, though, can read from only exactly one channel. If multiple sinks read from the same channel, it is guaranteed that exactly one sink will read a specific event from the channel.
Sinks poll their respective channels continuously to read and remove events. The sinks push events to the next hop, or to the final destination. Once the data is safely at the next hop or at its destination, the sinks inform the channels, via transaction commits, that those events can now be deleted from the channels.
Figure 2-1 shows a simple Flume agent with a single source, channel, and sink.
Figure 2-1. A simple Flume agent with one source, channel, and sink
Additional Components of Flume Agent
What we have discussed above are the primitive components of the agent. In addition to this, we have a few more components that play a vital role in transferring the events from the data generator to the centralized stores.
Interceptors
Interceptors are used to alter/inspect flume events which are transferred between source and channel.
Channel Selectors
These are used to determine which channel is to be opted to transfer the data in case of multiple channels. There are two types of channel selectors:
- Default channel selectors: These are also known as replicating channel selectors they replicates all the events in each channel.
- Multiplexing channel selectors: These decides the channel to send an event based on the address in the header of that event.
Sink Processors
These are used to invoke a particular sink from the selected group of sinks. These are used to create failover paths for your sinks or load balance events across multiple sinks from a channel.
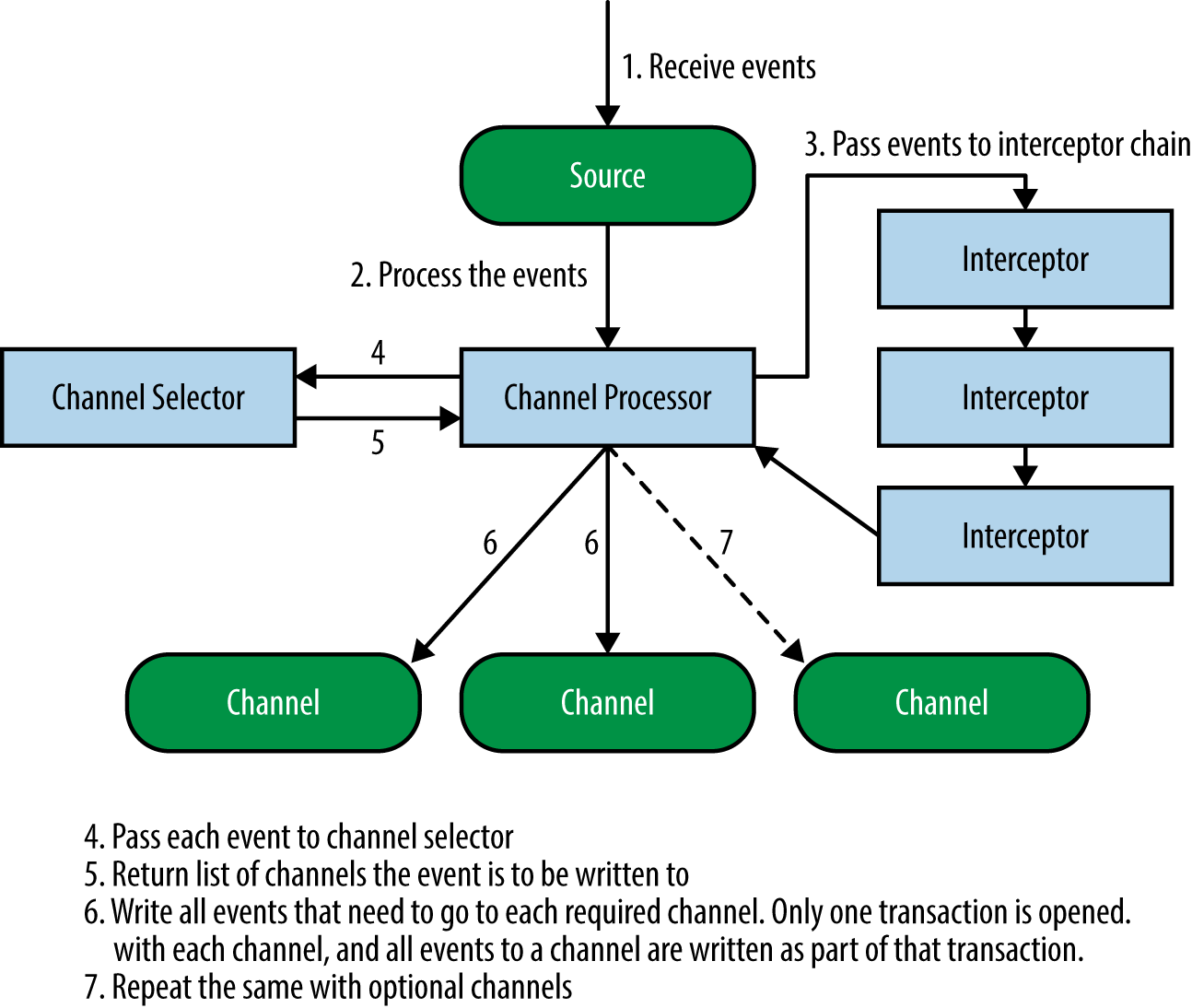
Flume itself does not restrict the number of sources, channels, and sinks in an agent. Therefore, it is possible for Flume sources to receive events and, through configuration, replicate the events to multiple destinations. This is made possible by the fact that sources actually write data to channels via channel processors, interceptors, and channel selectors.
Each source has its own channel processor. Each time the source writes data to the channels, it does so by delegating this task to its channel processor. The channel processor then passes these events to one or more interceptors configured for the source.
An interceptor is a piece of code that can read the event and modify or drop the event based on some processing it does. Interceptors can be used to drop events based on some criteria, like a regex, add new headers to events or remove existing ones, etc. Each source can be configured to use multiple interceptors, which are called in the order defined by the configuration, with the result of one interceptor passed to the next in the chain. This is called the chain-of-responsibility design pattern. Once the interceptors are done processing the events, the list of events returned by the interceptor chain is passed to the list of channels selected for every event in the list by the channel selector.
A source can write to multiple channels via the processor-interceptor-selector route. Channel selectors are the components that decide which channels attached to this source each event must be written to. Interceptors can thus be used to insert or remove data from events so that channel selectors may apply some criteria on these events to decide which channels the events must be written to. Channel selectors can apply arbitrary filtering criteria to events to decide which channels each event must be written to, and which channels are required and optional.
A failure to write to a required channel causes the channel processor to throw a ChannelException to indicate that the source must retry the event (all events that are in that transaction, actually), while a failure to write to an optional channel is simply ignored. Once the events are written out, the processor indicates success to the source, which may send out an acknowledgment (ACK) to the system that sent the event and continue accepting more events.
Figure 2-2 shows this workflow.
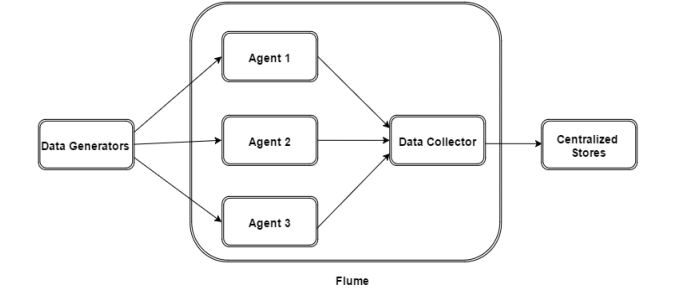
. Flume is a framework which is used to move log data into HDFS. Generally events and log data are generated by the log servers and these servers have Flume agents running on them. These agents receive the data from the data generators.
The data in these agents will be collected by an intermediate node known as Collector. Just like agents, there can be multiple collectors in Flume.
Finally, the data from all these collectors will be aggregated and pushed to a centralized store such as HBase or HDFS. The following diagram explains the data flow in Flume.
Flume data flow
Basically, we use a framework Flume to transfer log data into HDFS. However, we can say events and log data are generated by the log servers. Also, these servers have Flume agents running on them. Moreover, these agents receive the data from the data generators.
To be more specific, in Flume there is an intermediate node which collects the data in these agents, that nodes are what we call as Collector. As same as agents, in Flume, there can be multiple collectors.
Let’s revise Apache Flume Architecture & Flume Features
Afterwards, from all these collectors the data will be aggregated and pushed to a centralized store. Such as HBase or HDFS. To understand better, refer the following Flume Data Flow diagram, it explains Flume Data Flow model.
Types of Data Flow in Flume
a.Multi-hop Flow
Within Flume, there can be multiple agents and before reaching the final destination, an event may travel through more than one agent. This is known as multi-hop flow.
b.Fan-out Flow
The dataflow from one source to multiple channels is known as fan-out flow. It is of two types:
- Replicating: The data flow where the data will be replicated in all the configured channels.
- Multiplexing: The data flow where the data will be sent to a selected channel which is mentioned in the header of the event.
Fan-in Flow
The data flow in which the data will be transferred from many sources to one channel is known as fan-in flow.
Failure Handling
In Flume, for each event, two transactions take place: one at the sender and one at the receiver. The sender sends events to the receiver. Soon after receiving the data, the receiver commits its own transaction and sends a “received” signal to the sender. After receiving the signal, the sender commits its transaction. (Sender will not commit its transaction till it receives a signal from the receiver.)